| Mon, 5 Jun 2017
Right Sort Of Mad[originally posted on 27 Oct 2015] I would like to draw your attention to a few splendid projects which are, like Jack Churchill, The Right Sort Of Mad.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 8 Jan 2014
The Hobbit, pt 2
So I went to see The Hobbit, part 2, at the Imax. In 3D, despite my misgivings from last time. It is again a jolly fun romp, and worth seeing. The technology still has problems. Scenes with lots of movement are blurry and juddery. If I didn't know better I'd swear that they'd run out of time on the rendering farm to render all the frames, and so just doubled frames up to drop the effective frame rate from 24 fps to 12 or 18 fps. Apart from this, however, the use of 3D was a lot more effective. It seemed in the previous film that there were only a small number of layers at different distances from the viewer. This time, it looked far more like true 3D. In some sequences it was very effective indeed. However, there are still problems. People often look like 2D cutouts in a 3D scene. I can only assume that this is because Peter Jackson had an attack of the OMGWTF3DBBQLOLLERSKATE and so made all the CGI components (and they're present in most shots to some degree) have more depth than they should. In some cases he went way too far, and while the 3D was very effective it made me a bit dizzy. Yes, spinning and falling down a shaft would do that to a soul, and he recreates the feeling faithfully. However, it needs to be remembered that his film is a work of entertainment, not a training simulator for astronauts, and so he needs to tone it the fuck down. Last time, I was decidedly "meh" about the whole 3D thing, giving the technology just two stars. This time, I can say that it definitely helped in some places. Perhaps the technology has moved on, or perhaps the director and his post-production crew, with a bit more 3D experience under their belts, are simply better at their craft. Whatever the reason, I'm reasonably positive about it, and I now think that 3D can add to a film. This one, however, I think I'd still prefer to watch in 2D. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 16 Aug 2013
Today I Learned ...When storing a past event, always convert it into UTC and store it that way (I knew that). But when storing a future event (esp. if it's more than a year in the future), store it in the local timezone and only convert to UTC on the given day. This way you can properly handle the changes to time zones and/or daylight savings that might happen in the meantime. (via Domm's blog) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 14 Jun 2013
MathML browser extensionsIt's really annoying that there still isn't universal support for MathML. Things have got better recently though, with Safari finally supporting it. Of the major browsers, though, there are still two that don't. First, IE. It doesn't matter. It is only used for three things: first, to download a browser that doesn't suck; second, if it is chosen by someone who is stupid, ignorant or malicious; third, by people who need to compare browsers. Second, Chrome. Despite its lack of MathML, Chrome is IMO the best browser out there. It works on multiple platforms, has lots of extensions available, and has very good support for synchronising things like bookmarks and open pages across devices. And now there's a plugin for it to support MathML! And of course Chrome supports it without a plugin on iOS, because it uses the Safari rendering engine there. update: Safari on the desktop still doesn't render it particularly well, despite it working just fine on my phone. Huzzah! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 1 Jan 2013
The Hobbit, in 3d
I've now seen The Hobbit (part 1) in both 2d at the Hastings Fleapit and 3d at the BFI Imax. In 2d the only real complaints I had were that the font used for the film titles and credits hadn't been rendered well - it was all pixelly - and that the font used for subtitles when characters were muttering in Tolkienish was crap. Both of those are fixed in the 3d version. Unfortunately, some other stuff got broken. In those long sweeping shots with lots of movement that Peter Jackson loves so much, everything is just a little bit blurry. Even when there's not much movement, such as in close-ups, it's not quite as crisp as it should be. I believe that this is down to how the 3d system works: the images for the left and right eye are projected slightly offset from each other, and polarised 90° apart. The cheap n nasty plastic glasses you get to wear are polarised so each eye sees the right image. Trouble is, everyone's eyes are slightly different distances apart, and so it's only a very lucky few whose eyes are exactly the right distance apart who will see clearly. A handful of scenes and shots definitely benefitted from 3d, but only a handful. I'll not go out of my way to see a film in 3d again, and nor should you. You should see The Hobbit, but seeing it in 2d is fine. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mon, 12 Nov 2012
Python is shit!Apparently, perl is rubbish because <whine>the tools aren't friendly</whine>. Well, if that's the case, then python is too:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 7 Jun 2012
Google are naughty little liars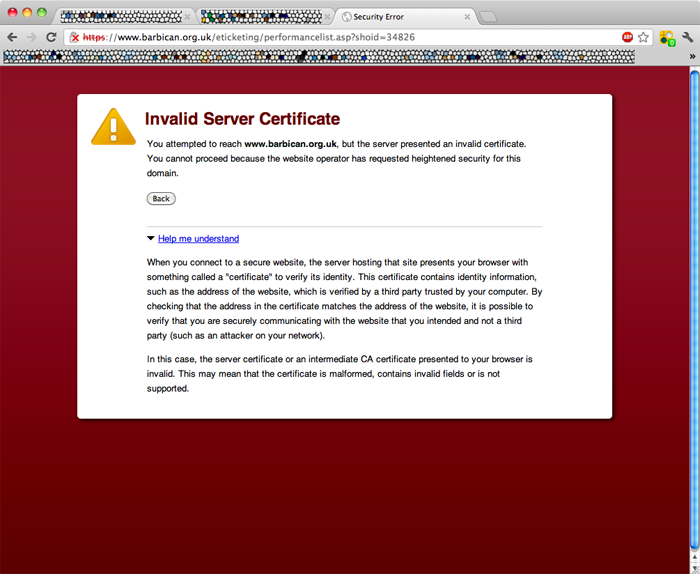 [click image to embiggen] Oh dearie me. I was trying to buy some tickets to a show at the Barbican, and got this error from Google Chrome. Translating into words that actually mean something useful instead of their "helpful" message, they're saying that the Barbican's SSL certificate couldn't be validated. Unlike every other browser, they provide no way for those of us who know what the hell this means to work around the problem. Thankfully, I have another browser - Firefox - available, so I could use that. Lo and behold, Firefox thinks that the certificate is Just Fine, and shows me that it's authenticated by Verisign. Why on earth would Google not accept this cert? Dipshits. 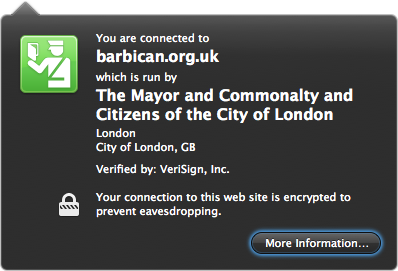 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 12 Apr 2012
I Love GithubGithub makes accepting patches from other people and applying them soooooo easy! Instead of having to extract the patch from an email onto my workstation and manually apply it, applying this contribution was a simple matter of clicking on one button. Thanks Mark - and thanks Github as well! And I was also amused to see that the new release of Net::Random was exactly five years after the previous one. This adds support for fetching your randomness over SSL. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 29 Sep 2011
Amazon Kindle wireless bug - and a bugfixI recently bought a Kindle e-book reader (I'll post a full review later after I've had another week or so of using it) and first impressions are pretty good. Not great, but pretty good. There was, however, one big problem. It couldn't connect to my wireless network, whose base-station is a Mac Mini running OS X. I talked to a nice lady in Amazon's customer support department, but after getting me to send my Kindle's logs, and having Amazon's engineers look at them, the best she could say was "your router isn't configured properly". I'm afraid it is configured properly, and everything else - my phone, my iPad, my Linux laptop, my Mac laptop - can talk to it just fine. The only thing that can't is my Kindle. This is because of a bug in the Kindle's DHCP client. In DHCPDISCOVER messages, the 'secs' field is meant to be set to the number of seconds since the DHCP process started. Many DHCP servers, including (in my case) Apple servers are configured by default to ignore such messages if 'secs' is set to zero, as this indicates a client that isn't fully running yet so any reply may not be noticed. A compliant client will retry if it gets no response, and after a few seconds of retrying 'secs' will be above whatever the server's threshold is, and everything will work. It seems that the Kindle always puts a 0 in that field, in violation of the standard. To work around it on your Mac, do the following, in this order. I assume Mac OS X 10.6, it may be a bit different in others:
I have emailed the nice lady at Amazon and told her that I have a solution, and that Amazon can have the solution in exchange for a 20 quid gift voucher. Seems only fair, given that people have been complaining on Kindle-ish forums about not being able to use Apple base stations ever since the Kindle was launched. I'm really surprised that Amazon haven't figured it out. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 8 Sep 2011
The TudorsI know, it's TV. And is therefore crap by default. But I started watching it, under the misapprehension that Henry VIII was played by The Blessèd Brian. I was wrong, he instead appears in Henry 8.0, which, incidentally, is jolly good and you should watch it. But The Tudors is pretty good too. So far I've only watched the first series, and I do expect it to go downhill in subsequent ones, but overall it was enjoyable, and I recommend it. While there are some "departures from history", it is overall reasonably accurate, in particular in its portrayal of the King and his confidantes Wolsey, Cromwell, and the clever, erudite but nasty "saint" Thomas More. How you can declare someone to be saintly when he imprisoned people merely for their beliefs or who approved of burning people to death is beyond me. I suppose it requires the same sort of perverted mindset that thinks it's OK to hide rapists. It was only spoilt a teensy bit for me by some glaring anachronisms, all of which could have been avoided without changing the story one iota:
Do I win a gold star for pedantry? | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 23 Jul 2011
Splitting a git repositoryFor several years I've kept all my perl source code under version control. This is good. However, I was keeping all my distributions - all 40-odd of them - in a single repository. This is bad. It means that anyone who wants to check out the code has to check out 40 distributions, some of them very big, that they're not interested in as well as the one they are interested in. So I've split the repository up into lots of seperate ones, and I've uplaoded them to Github instead of keeping them on my own machine. Normally I'm dead set against uploading my data to Teh Clowd, because you lose control over it and it's hard to make backups. Git and Github are an exception to this. My own checkouts - on my laptop and elsewhere - are complete copies of the entire repository, so if Github were to go out of business overnight, I'd not lose a damned thing, I'd just need to find somewhere else to act as the public front-end for my repositories. And it's all stuff that I want to be public anyway, so I really don't care if they lose a copy! Splitting a git repository while still keeping all the history is a bit tricky, but the lovely Paul Johnson gave me a recipe, which I reproduce here with a few minor changes. Assuming that your monolithic repository contains a bunch of directories, each of which is to become a seperate repository ... mkdir split-repo This leaves the original repository unchanged, so if anything goes wrong you need not worry. I did get some warnings and errors from 'git gc' and 'git prune' about it being out of memory when trying to compress files, but that's because my repository has some very big files. These errors were in fact harmless and just meant that the new copies of the repositories on my laptop were wasting lots of disk space. Once I'd uploaded them to github, deleted the local copy, and then re-downloaded from github, that was fixed. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 6 Jul 2011
Star ratings re-revisitedI did, very briefly, consider a completely different rating system for my reviews, instead of just awarding 0 to 5 shiny gold stars. I considered rating books out of ten on several axes - for example, entertainment, literary merit, imagination, consistency. I would then combine them by treating those scores as the co-ordinates of a point in an N-dimensional space, the overall rating being the distance of that point from the origin, or equivalently, they are components of a velocity vector in an N-dimensional space. Let me give a couple of examples: The Quantum Thief might score 8/10 for entertainment, 10/10 for literary merit, 9/10 for imagination, and 10/10 for consistency. The score, then, is sqrt(82+102+92+102) = 18.6. A perfect score on those axes would be sqrt(4*102) = 20. So to normalise to a score out of ten we divide by 2, giving 9.3/10. I actually gave it 5/5. A Mighty Fortress, on the other hand, might get 5/10 for entertainment, 2/10 for literary merit, 2/10 for imagination, and 8/10 for consistency, for a score of 9.8, which normalises to 4.9/10. I actually gave it 2/5. There are at least three obvious reasons why I didn't go with this.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mon, 20 Jun 2011
Star ratings revisitedJust over a year ago I started awarding books and things that I reviewed shiny gold stars. I also retrospectively scattered stars on some of my older reviews. I thought it would be a good idea to see how many of each I'm awarding, and so how well I'm sticking to my rating system. I'm expecting a normal distribution, with the mean somewhat above 3 stars to reflect the fact that I deliberately don't read shite, and that lots of what I read is because other people have raved about it. Well, the results are in ...
I think this is good. It's roughly what I'd expect given my reviewing criteria and the small number of options available. If I had a larger scale to work with - if, say, I was awarding marks out of 20 - I'd expect a smoother drop-off, and at both ends instead of just at the bottom end. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 10 Mar 2011
Meet BrambleUntil recently, this 'ere blog was run using the excellent Bryar software, which I maintained after its original author stopped supporting when he stopped being a programmer and went off to Save The Heathen. Bryar fitted by needs and worked well, but it had several features that I just never used, and others that were never fully implemented. I added a few features that I wanted, but it was getting harder and harder to hack on as my needs diverged more and more from Simon's. So a few weeks ago, I wrote my own replacement from scratch. It's called Bramble, because areas of bramble bushes are sometimes called a briar patch. You probably didn't notice when I deployed it, because it supports all the old URLs so nothing broke*. And by leaving out support for stuff that I never used anyway, it's become easier to add shiny new features. For example, it was about 30 seconds work to make it support wildcards in IDs, so if you want to see all my book reviews you can click here. Naturally, these views of the data are also available in RSS. * you may have wondered why it re-published everything one night in the RSS feeds - that's because the canonical URLs of all my posts changed. They now look REST-ish, like | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 17 Feb 2011
CPAN Testers' CPAN author FAQBarbie recently posted that David Golden recently posted regarding a comment from Leon Timmermans on IRC. Leon highlighted a problem when CPAN authors try to find information about CPAN Testers, and how they can request testers to do (or not do) something with a distribution they've just uploaded. The page they are looking for is the CPAN Author FAQ on the CPAN Testers Wiki. Although there is plenty of information for authors, the page doesn't appear prominently on search engines when some searches for that kind of information. As such, David has suggested that people tweet or post about the page, which includes this post :-) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 10 Sep 2010
Webkit and ASCIIMathMLAs you will no doubt know by now, I occasionally perpetrate mathematics. But it sucks to have to say in something like this "take the product of p(i)int(n/p(i)) for i=1 to i=Φ(n)". It would be much better if I could embed a proper formula. There's a standard way of doing this, called MathML, and it's fucking horrible. And in any case, browser support for MathML is piss-poor. However, it's getting better - Firefox now supports it fairly well, and Webkit does too, although not quite as well as Firefox. There are also a few useful tools for making MathML suck less, in particular ASCIIMathML, which I am now using. Using that, I type the above equation thus: \prod_(i=1)^(\phi(n))p(i)^(\lfloorn/(p(i))\rfloor) and it renders thus in your browser: `\prod_(i=1)^(\phi(n))p(i)^(\lfloorn/(p(i))\rfloor)` it should render something like this: Note that at the time of writing, Webkit doesn't properly render the floor(n/p(i)) as a superscript to p(i). Even with the flaws in common browsers (and the complete lack of support in many, including Safari) I'm going to start using it, because it's just so damned useful. Webkit and Firefox support it, which is good enough for me, and because Webkit is really just the nightly builds of Safari, we can expect a near-future release of Safari to support it too. Incidentally, this journal entry exposes a bug in ASCIIMathML as well as in the current Webkit - can you spot it? Update: it took the author of ASCIIMathML mere hours to respond to my bug report with a fix. Makes me rather ashamed of some of the bugs that have been mouldering in my RT queue for over a year :-) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 3 Sep 2010
Travelling in time: the CP2000ANMy mad experiment in CPAN mirrors has grown a couple of new tentacles. Previously it could be a perl-X.Y.Z-specific mirror, such as the CP5.6.2AN, or an OS-specific mirror such as the cpMSWin32an. Now it can combine the two such as in the CP5.8.8-irixAN and all of those can optionally be combined with a date/time to only include stuff that was already on the CPAN as at that time, such as at the CP2000AN. Why do this? Let's assume that you have a large complex application which uses lots of stuff from the CPAN, and depends on Elk version 1.009 and ListOfDogs version 5.1, and will break with any later version of Elk (or of ListOfDogs). You get a feature request from a user, and think "ah-ha, there's a module for that", and so you go to install Some::Module. Unfortunately, the latest version of Some::Module depends on Some::Other::Module which in turn needs Another::Module which needs Elk 1.234, so your CPAN client merrily upgrades Elk, breaking everything. Doom and Disaster. Having a CPAN "mirror" nailed to the date of the last release of Elk and ListOfDogs that works for you will save you from pain, suffering, and the Dark Side. Either you'll get older versions that Just Work, or you'll get nothing, and nothing is far better than breaking everything! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 31 Jan 2010
Negative keywordsNearly three years ago I added keyword support to this 'ere journal. Well, now it supports negative keyword filtering. So if you want to see posts that are not tagged "geeky", for example, here's the linky. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
CPANdeps upgradeWhile you won't notice any changes, there have been biiiig upgrades at CPANdeps. Here's the diff. Until now, it's used a SQLite database of test results that I downloaded every day and then mangled a bit to do things like add some necessary indices, figure out which reports are from dev versions of perl, and so on. That worked really well back in the summer of 2007, when there were only half a million reports in the database. I started worrying a bit at the beginning of 2009 when we hit 3 million, but the update happened overnight so I didn't care. But now that we've got over 6 million reports, the update would take anywhere between 8 and 14 hours. Not only is that not sustainable given the current growth rate, it also hurts the other users on that machine, because almost all of that time is spent waiting for disk I/O - which means that they're also waiting for the disk. On top of that, when you have big databases, a SQLite CGI ain't a great idea because indices have to be fetched from disk every time, so reads pound the disk too. Doubleplusungood! Fun fact: SQLite is great for prototyping, but it doesn't scale :-) So now it uses MySQL. Having a database daemon running all the time means that there's now some caching, so reads are quicker. In addition, given that I can't just simply fiddle with the structure of the database that I download to produce what I want, and instead have to import the data into MySQL, it now only imports new records, so the daily update takes only a few seconds. I also re-jigged the structure of how it caches test results. Instead of being all in one directory with hundreds of thousands of files, they're split into a hierarchy. This probably won't have any significant effect on normal operations, but it will certainly make it faster for me to navigate around and see what's going on when people submit bug reports! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mon, 4 Jan 2010
Broken out of jailToday I jailbroke my phone, using the stupidly named blackra1n, and following the step-by-step guide here. There were a couple of points during the jailbreak at which iTunes tried to start - presumably something it did made the iPhone appear to have been just plugged in and so iTunes tried to start, and so I killed iTunes each time with extreme prejudice before it had a chance to communicate with the iPhone and potentially brick it. In retrospect, I should have turned that off in iTunes first before doing this. Everything seems to have worked just fine. So far I've found and installed the following apps:
What other apps should I try out? The quality of non-Appstore apps is definitely lower than that of officially sanctioned ones in the Apple Appstore - a few others that I've tried, in particular Winterboard and Terminal, have been quite buggy and I've removed them. Even so, it's the user's choice to install dodgy software from third parties, and Apple shouldn't make it so hard for people to shoot themselves in the foot if they want to do that. Either they should allow unvetted apps into the Appstore (and have it pop up a gigantic warning every time you try to install one, and segregate them in a ghetto so that you don't accidentally stumble across them) or they should officially support installing apps from third-party sources (again with warnings). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 3 Oct 2009
Graphing tool
Update: now 48.3% even shinier - see on the right | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 30 Sep 2009
Optimising n! - revisited againFor the background, see this post and this post. I have had An Branewave! When I said that 100! = 250 * 333 * 520 * 714 * 119 * ... was wrong (which it is) I stupidly didn't realise that there is a pattern to the missing terms. The 250 comes from observing that there a 50 multiples of 2 less than or equal to 100. There are also 25 multiples of 4 (also known as 22), 12 multiples of 8 (aka 23), 6 multiples of 24, 3 multiples of 25, and 1 of 26. the 25 multiples of 4 contribute another 225. The 12 multiples of 8 (which of course are also multiples of 4) contribute another 212, and so on. So we see that 100! is divisible by 250 + 25 + 12 + 6 + 3 + 1, or 297. There is, of course, a similar pattern for all the other prime factors. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 25 Sep 2009
Combining functionsThere was a great programme on Radio 4 yesterday about Newton and Leibnitz. I'm not sure why, but it inspired me to consider the curve that is constructed from It can obviously be done. Consider that to fit a curve to any* three points, you can do it with a curve I'm sure that this can be done - obviously you can't actually calculate an infinite number of constants, but I'm sure that with a bit of integration it could be done. And it can be done for any such pair of functions which meet at a point. However, on further reflection I'm not entirely convinced that it can be done in the general case - you have that pesky discontinuous yes/no conditional in the middle: "is x <= n?". * not strictly true - consider (0,0), (0,1), (1,0). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 16 Aug 2009
AntibodyMXThe nice people at AntibodyMX said they'd de-spamify my email for me for free provided I wrote a review. They didn't say it had to be a good review :-) so I took them up on it. I've previously been rather sceptical about such services. There are obvious concerns about privacy from having all your mail go through someone elses systems instead of going - as far as is possible - straight from the sender to you. If you use TLS (and you should) then even if your mail transits someone elses network, they won't be able to read it. With an outsourced service like AntibodyMX's, they can, because mail is sent to them and they then forward it on to me. That they can see the plain-text of my email is, however, necessary for the filtering to work. And in practice, it's not a significant concern at least for individuals, because my mail just isn't that interesting. My other source for scepticism was that they probably couldn't do a better job than I could. Indeed, because their service has to work for everyone there are ways in which they can only possibly do a worse job at filtering mail than I can. For example, I can throw away all mail in Chinese, Russian, Japanese and Hebrew, because all mail in those languages is unreadable so even if it's not spam (yeah right) I still don't lose out by ignoring it. They can't do that, because I'm sure they have some customers who get some legitimate mail in weird languages that aren't written right. Without tools like that, then surely they can't do a better job than me - after all, the software they use is the same that's availabe to me, and I've been successfully de-spammifying my email for years. So why did I switch? Simply because I got fed up maintaining my anti-spam systems. They eat valuable memory and CPU - and eat more by the day as I have to keep adding more filters to combat spammers' evil imaginations. Maintaining all that takes time. Due to having more interesting things to do, I was beginning to fall behind on keeping my filters up to date, and more spam was sneaking through. When I got the offer to use their services for free, I decided to take them up on it. After all, there's no real downside. If it doesn't work as well as advertised, I can trivially switch back to doing the job myself. But I won't be switching back to doing the job myself. The AntibodyMX service Just Works. That, however, is with the service being free. It's a different matter entirely if you have to pay for it. According to their website, prices start at £115 a year. When you think about how much time your company's sysadmins put in to spam control, it's a no-brainer and is easily worth paying. It's only really worth thinking about if privacy is particularly important to you. I wouldn't want, for example, my doctor or solicitor or MP to use any such service. Not because they can't trust the service providers, but because they shouldn't trust anybody. Doubly so if using a service provider in another country. For personal use I think £115 would be a bit steep. It is worth paying for, I'm just not sure how much I'd shell out. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
cgit syntax highlightingNB: since writing this I have migrated all my code to Github and stopped using cgit. Therefore many of the links no longer work For the last few months I've been using git for my version control system. It's better than CVS because it can handle offline commits. So if I'm using my laptop on a train, I can still use version control without having to have a notwork connection. And to give a pretty web front-end to it for other people to read code without having to check it out of the repository, I use cgit, which I mostly chose because it's a dead simple CGI and not a huge fancy application. One problem with cgit is that by default it doesn't do code highlighting. But it has the ability to run blobs of code through any filter you care to name before displaying them, so to get something nice like this all you need to do is write a highlighter and add a single line to your cgitrc:
My highlighter program is this: 1 #!/usr/local/bin/perl
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 1 Aug 2009
Devel::CheckLib can now check libraries' contentsDevel::CheckLib has grown a new feature. As well as checking that libraries and headers exist, it can now also check that particular functions exist in a library and check their return values. This will be particularly useful if you need to check that a particular version of a library is available. It works if you have a Unixish toolchain. I need to wait for the CPAN-testers reports to see if I managed not to break anything on Windows. Unfortunately, even though the lovely Mr. Alias has worked hard to make Windows machines available to developers, I found it to be just too hard to use. Even downloading my code to the Windows machine was hard, as Windows seemed to think it knew better and shouldn't download the file I told it to download. Then once I had downloaded it, Windows decided to hide it somewhere that I couldn't get to using the command line. So I gave up. I might try again once there are some decent tools on the machines: wget, tar, and gzip at minimum, as given those I can quickly bootstrap anything else. Software development isn't just about having compilers available. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 17 Jul 2009
Journal now with another 30% more shiny!Nearly three years ago I put some funky shit in the pages for this journal. I've finally got round to adding more funky shit - namely the expanding menus on the left. There's also a spiffy new section there showing posts that have recently received comments. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 28 May 2009
Bryar security holeSomeone on IRC reported a bug in Bryar. Namely that a Naughty Person can exploit the feature that notifies you of blog-spam by email to execute arbitrary code on your machine, as the user you run Bryar under. A patched release is on the way to the CPAN, and you are strongly urged to upgrade. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 21 May 2009
POD includesOne of my CPAN distributions is CPAN-FindDependencies. It contains a module CPAN::FindDependencies, and a simple script that wraps around it so you can view dependencies easily from the command line. That script, naturally, has a man page. However, that manpage basically says "if you want to know what arguments this program takes, see the CPAN::FindDependencies docs". This is Bad from a usability point of view, good from a not-duplicating-stuff point of view, and good from a laziness point of view. Which means that it's Bad. So, the solution. =over and some Magic that does the cpp-stylee substitution at This is, of course, crying out to be made less horribly hacky, but it works for now, so I'm happy. My original idea was to write some crazy shit that would do the #include at install-time, when the user was installing my code. But that has the disadvantage that tools like search.cpan wouldn't show it properly, as they simply look at the files in the distribution. So this does the #includes at the last moment just before I package up the code and upload to the PAUSE. You lovely people get the right documentation in all the right places, I only have to maintain it in one place so it stays in sync, and (in the interests of Laziness) I don't have to remember to run any extra scripts before releasing, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 28 Apr 2009
Factoring FactorialsTake a factorial. Any factorial. Factor it*. Notice a Pattern. That pattern is that if you list all of the prime factors in order and the number of times they appear, at no point does any larger factor appear more often than any smaller factor. This would appear to be obvious, and it "obviously" applies to all factorials** (I've verified it by hand up to 28!, at which point I got bored). But I'm finding it hard to put a proof into words - or more concisely but equivalently - into symbols. * this is easy. While factoring 1124000727777607680000 might be quite hard, if you know that it's 22! it becomes trivial because we know that it is divisible by 2, 3, 4, 5, ..., 21, 22, each of which is trivially factorable. Given that each number is the product of a unique set*** of factors, the factors of 22! can only be the set of all the factors of all the numbers we multipled to get 22!. Easy! ** it becomes obvious when you consider Eratosthenes' method for testing primality. *** yes, I know, it's not really a set. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 7 Mar 2009
Migrating to GitI wanted to be able to commit to my CVS repository while I was offline - eg while using my laptop on a train. But CVS doesn't support that, and to make it pretend to support it would involve some quite monstrous hacks. Of the commonly used VCSes, only git supports offline commits, so I decided to try that instead. There are some excellent instructions here which mostly Just Work. Mostly. There are two small flaws. First, it died importing this file. I couldn't be bothered to analyse why, and just deleted it and its history from the local copy I'd made of the repository (I used rsync to suck it down from Sourceforge). Contrary to the documentation, 'git cvsimport' does not carry on where it left off if it gets interrupted half way through, so once I'd deleted the offending file I had to also delete the broken git repo and start again. Once it had finished I then added the most recent version of the file to the git repo in the usual way. So I lost the history of that file. Thankfully it doesn't matter in this case. The second flaw is a minor one. It tells you to delete the repo's contents leaving just the .git directory, thus making it a "bare" repository. But it doesn't tell you that you have to edit .git/config and set the "bare" variable to true. If you don't do that, you'll get spurious warnings when you do a 'git push'. First impressions of using git as "CVS with offline commits" are good. It works very well for a single user editing code in various different places throughout the day. I have yet to experiment with multiple concurrent edits. While I'm sure it works well if you use git in a distributed fashion, I still don't quite trust it to work in a similar fashion to CVS, with multiple users pushing changes to a central repository. But if I have any problems, you can be sure I'll grumble about them in my use.perl journal. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 21 Jan 2009
Linuxbierwanderung 2010 proposalDavid Harris and I have put forward a modest proposal to hold the 2010 Linuxbierwanderung in Alfriston, near the Sussex coast. All discussion should be kept on the LBW mailing list. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 1 Jan 2009
Permalink | 0 Comments | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 21 Oct 2008
Thanks, Yahoo![originally posted on Apr 3 2008] I'd like to express my warm thanks to the lovely people at Yahoo and in particular to their bot-herders. Until quite recently, their web-crawling bots had most irritatingly obeyed robot exclusion rules in the robots.txt file that I have on CPANdeps. But in the last couple of weeks they've got rid of that niggling little exclusion so now they're indexing all of the CPAN's dependencies through my site! And for the benefit of their important customers, they're doing it nice and quickly - a request every few seconds instead of the pedestrian once every few minutes that gentler bots use. Unfortunately, because generating a dependency tree takes more time than they were allowing between requests, they were filling up my process table, and all my memory, and eating all the CPU, and the only way to get back into the machine was by power-cycling it. So it is with the deepest of regrets that I have had to exclude them. [update] For fuck's sake, they're doing it again from a different netblock! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 27 Aug 2008
Optimising n! - revisitedFor the background, see this post. Late one night I thought that you might be able to simplify n-factorial thus: `\prod_(i=1)^(\phi(n))p(i)^(\lfloorn/(p(i))\rfloor)` Where:
Now, without using a lookup table, p() and Φ() are hard to calculate, but at least you'd avoid a lot of the problems that come from using the stupendously big numbers that come as intermediate results in calculating factorials. Unfortunately, that formula is wrong anyway. It's a restatement of this: 100! = 250 * 333 * 520 * 714 * 119 * ... which came from noticing that 100! is the product of 50 numbers which have 2 as a prime factor, 33 numbers which have 3 as a prime factor, 20 numbers that have 5 as a prime factor, and so on. Unfortunately, it doesn't take account of numbers like 4 and 18 which have a repeated prime factor - 4, for example, is 2 * 2 and 18 is 2 * 3 * 3. Bother. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 22 Jul 2008
Wikipedia: WRONG AGAINWikipedia has a reputation for being of rather low quality, particularly in the humanities. In the sciences and technology it is supposed to be pretty good. But today, I found an error in their article about ... the triangle. One of the most basic mathematical concepts. And they got it wrong. Joy. OK, to be fair, it's only subtlely wrong, is correct for the majority of cases, and one could argue that the context in which the inaccurate information is presented makes it OK. But I disagree. In a section called "Basic facts" they first mention that triangles were described thoroughly by Euclid. Good. In the next paragraph, they say that the internal angles add up to 180°. Not so good. They only do so in some spaces, the most commonly known of which is the Euclidean space. Anyway [click click click type click] I've fixed it now. I wonder how long it'll stay fixed, or whether some wanker will revert my pedantry. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 25 Jun 2008
Why you should release your company's codeGeeks often want to release some of the code they write at work as open source. But often they don't really have any good idea why they should do it, other than that it feels like the right thing to do. Well, here's a damned good reason for you, and what's more, it's one that your boss will like. Just under two weeks ago, I released some of my code. I didn't really expect anyone else to be particularly interested in it, but releasing it couldn't do any harm. But a few days later, someone submitted a bug report. What's more, he included a patch, and regression tests. If I hadn't released my code, it would still have bugs in it, which would no doubt bite me in the arse later and figuring out what was going wrong would waste a lot of my time. By releasing my code, I got someone else to test and fix my code for free. So now, when your boss asks you to justify releasing the code you've written for him, point him at this post, and tell him "open source bugs get fixed by other people, for free". The most recent version of the code in question, including the bugfix, can be found here. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 11 Jun 2008
Optimising n!If you want to add up all the numbers from 1 to n, you can do it two ways. The slow, inefficient way is to calculate: 1 + 2 + 3 + ... + n The quick way is to remember what you were taught in school, that: 1 + 2 + 3 + 4 + 5 + 6 = (6 + 1) + (2 + 5) + (3 + 4) = 7 + 7 + 7 and that in general: 1 + 2 + ... + n = n(n+1)/2 This optimisation might not matter for small values of n, but for n = 1000000 it really makes a big difference. This got me thinking whether there was a similar trick for calculating the product of all numbers from 1 to n - that is, n-factorial, or n!. This matters even more for n! because it gets so large so quickly that computers are unable to accurately represent the intermediate values. In fact, 20! is the largest that can be respresented on a 64 bit machine. 21! can only be approximated, as you need to use a floating point number. This means that not only is calculating really big factorials time-consuming, it's not possible at all to do it accurately with native datatypes. I don't even know if there is a simple re-statement of n! like there is for the sum above, but I'm gonna spend a few idle minutes working on it. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
Per-user resolv.conf filesI want per-user resolv.conf files. I've mentioned this in a couple of places and got asked why. It's so that I can have a consistent set of aliases everywhere I go (so I can, eg, type ssh sdf instead of ssh sverige.freeshell.org) and also so that the resolver will fill in my choice of domain on the end of hostnames, so I can be lazy and type ssh plough instead of ssh plough.barnyard.co.uk. Some quick googling didn't turn up anything usefully cross-platform, but the implementation shouldn't be too hard - just set LD_LIBRARY_PATH or LD_PRELOAD and provide my own resolver library. Unfortunately, the resolver is part of libc so I need to figure out how to:
Damn, I might have to read about how the linker actually works if I'm ever to do this. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 13 May 2008
Compact tag cloudsI've decided that using different sized text for the tag cloud works better than using different colours, but it has the drawback of eating a lot of screen space. I need to find an algorithm to pack the text in more efficiently so that it doesn't waste so much vertical space. Actually, I already have an algorithm to do it in my head. Unfortunately it's, umm, rather inefficient. In fact I think it's O(N!) which would be fine if I only had 10 tags, but I have 52 so far, and am still occasionally adding tags. 52! is roughly 8e69. That's 8 followed by 69 zeroes. 69, dude! Of course, this is a variant on the rectangular packing problem, which is itself a variant of the knapsack problem, which is NP-complete, so I'm going to have to come up with a heuristic that will return a reasonable (but not optimal) solution quickly. I've decided that the best heuristic is to ask for pointers to code that other people have written that will do the job for me :-) My constraints are that I need to fit an arbitrary number of rectangles of arbitrary size into a rectangle of fixed width but whose height can vary as necessary, with minimum wasted space. And I'd prefer a perl or javascript solution. Use both sides of the paper. No conferring. You may begin now. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mon, 31 Mar 2008
The value of backups, part 2Whenever someone grumbles online that they've lost some data, I always smugly suggest that they restore from their backups. After all, all of my stuff is backed up. I even test my backups because I also smugly tell people that "if you've not tested them you don't have backups, you have hopes". Well, I just found out the hard way that I'd forgotten to add one of my remote shell accounts to my daily backups. Oops. You may now all point and laugh. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 22 Dec 2007
To my anonymous benefactor ...Today I got a copy of "Haskell: the Craft of Functional Programming" in the post, which, while it's been on my wish list for ages, I'd not got round to actually buying. So - many thanks to whoever got it for me, it is most appreciated. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 23 Nov 2007
CPANdepsCPANdeps now lets you filter test results by perl version number, and also knows what modules were in core in which versions of perl. Hurrah! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 28 Oct 2007
Leopard? Not yet, thanks.I am most grateful to Geeklawyer for volunteering to beta-test the new version of OS X for me. Evri fule knoe that the first release of a piece of software is a steaming pile of shit, so *I* will wait at least another few weeks to make sure there's no horror stories before I buy it myself. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 19 Sep 2007
Talk Like A Pirate DayIn honour of Talk Like A Pirate Day, which has previously inspired me to write great software, I just released (well, committed to CVS anyway) arrsnapshot. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 14 Sep 2007
A Windows Programmer Writes ...According to a Windows programmer of my acquaintance who, to spare his blushes, will remain anonymous here: " The recognised way of communicating with a POP3 server to retrieve mail is to create an FTP connection and use that connection to send text commands to the POP3 server to download responses and messages. " The gentleman in question runs a company which "Develops stand alone or networked database applications, inventory databases, CRM systems, and help desk dall (sic) logging." With developers like that, it's no wonder that the Windows platform has software of such low quality. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 30 Aug 2007
YAPC::Europe 2007 report: day 3My Lightning Talk on cpandeps went down really well, although as José pointed out, I need to fix it to take account of File::Copy being broken. I also need to talk to Domm after the conference is over to see if I can get dependency information from CPANTS as well as from META.yml files. There were lots of other good lightning talks. Dmitri Karasik's regexes for doing OCR, Juerd Waalboer's Unicode::Semantics, and Renée Bäcker's Win32::GuiTest were especially noteworthy. Richard Foley's brief intro to the perl debugger was also useful. Unfortunately Hakim Cassimally's talk was about debugging web applications, which I'd not noticed on the schedule, so I didn't stay for that. And finally, Mark Fowler's grumble about why perl sucks (and what to do about it) had a few interesting little things in it. I am having vaguely sick ideas about mixing some of that up with an MJD-stylee parser. At the auction I paid €250 to have the Danish organisers of next year's YAPC::Europe wear the Swedish flag on their foreheads. This, I should point out, was Greg's idea. I would never be so evil on my own. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
YAPC::Europe 2007 report: day 2A day of not many talks, but lots of cool stuff. Damian was his usual crazy self, and MJD's talk on building parsers was really good. Although I probably won't use those techniques at work as functional programming seems to scare people. The conference dinner at a Heuriger on the outskirts of Vienna was great. The orga-punks had hired a small fleet of buses to get us there and back, and one of the sponsors laid on a great buffet. The local wine was pretty damned fine too, and then the evening de-generated into Schnapps, with toasts to Her Majesty, to her splendid navy, and to The Village People. It wasn't all debauchery in the evening though - on the bus, I had a very useful chat with Philippe about Net::Proxy, and re-designing it to make it easier to create new connectors for it. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 28 Aug 2007
YAPC::Europe 2007 report: day 1As is becoming normal, I used the times between talks to bugfix some of my modules - this time Tie::STDOUT and Data::Transactional. The former was failing on perl 5.6, the latter on 5.9.5. The former was a bug in perl (you can't localise tied filehandles and expect the tieing to go away in 5.6, so it now declares a dependency on 5.8), the latter was a bug in my code. Philippe Bruhat's talk on Net::Proxy was great - you can tell it's great because I came away with ideas for at least four things that I need to write. First up will be a plugin for it to allow the user to specify minimum and maximum permitted data rates for proxied connections. This will permit bandwidth limits for maximum permitted rates, but will also help to defeat IDSes doing traffic analysis if you specify a minimum permitted data rate. This will protect (eg) ssh sessions from being identified based on their very bursty traffic pattern, by "filling in the blanks" with junk data. In the evening, the CPAN-testers BOF was productive. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 3 Aug 2007
Module pre-requisites analyserAs a service to module authors, here is a tool to show a module's pre-requisites and the test results from the CPAN testers. So before you rely on something working as a pre-requisite for your code, have a look to see how reliable it and its dependencies are. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 29 Jul 2007
Palm Treo call db moduleTo make up for a disappointing gap in Palm's software for the Treo smartphone, I wrote a small perl script to parse the database that stores my call history. I then re-wrote it as a re-useable module which also figgers out whether the call was incoming or outgoing. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 21 Jul 2007
Wikipedia handheld proxyI got irritated at how hard it was to use Wikipedia on my Treo. There's so much rubbish splattered around their pages that it Just Doesn't Work on such a small screen. Given that no alternatives seemed to be available - at least, Google couldn't find any - I decided to write my own Wikipedia handheld proxy. It strips away all the useless rubbish that normally surrounds Wikipedia pages, as well as things like the editing functions which are also hard to use on portable devices. Internally, it's implemented using perl, LWP, and mod_perl, and is hosted by Keyweb.de. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 28 Jun 2007
YAPC::Europe 2007 travel plansI'm going to Vienna by train for YAPC::Europe. If you want to join me you'll need to book in advance, and probably quite some way in advance as some of these trains apparently get fully booked.
The first two legs of that are second class, cos first wasn't available on Eurostar (being a Friday evening it's one of the commuter Eurostars and gets booked up months and months in advance) and was way too spendy on the sleeper to Munich. Upgrading to first class from Munich to Vienna is cheap, so I have. Coming back it's first class all the way cos upgrading was nearly free ...
Don't even think about trying to book online or over the phone, or at the Eurostar ticket office at Waterloo. Your best bet is to go to the Rail Europe shop on Picadilly, opposite the Royal Academy and next to Fortnums. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 7 Jun 2007
Book review: Backup and RecoveryAuthor: Curtis Preston ISBN: 0-596-10246-1 Publisher: O'Reilly I contributed part of a chapter to this book, and so I got a free copy. I was expecting to take it home, put it on the shelf, and never use it. Today, less than 48 hours after getting the book in the post, I had to use it. The thoughtful comments and excellent description of how dump / restore work prevented me from looking like a complete tit on a public mailing list. I therefore recommend this book. More seriously, it does look jolly good, covering just about all the backupish stuff that I've heard of and lots that I haven't. But more importantly, it devotes lots of space to restoring your backups - complete with step-by-step instructions for "bare metal" recovery - and talks about things to do when your backups are broken. And it covers things that lots of admins don't like to think about, like Exchange and MySQL (and other databases; judging from a quick skim of the Oracle section I expect the coverage to be good). Buy a copy of this book for your friendly local sysadmin. He will love you for ever.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 3 Jun 2007
Palm GPS help wantedI'm looking for a combination of GPS hardware and software that I can use with my Treo 680. I'm sure that one of the many products I've looked at will do the job, but their websites are ever so unhelpful. I need to be able to plan waypoints in advance, record waypoints as I go, and have my position displayed on a moving map. I will supply the map files myself as bitmaps in any reasonable format. When I am near the edge of a map, the software should merge image segments from up to four map files. Anything that requires Windows is defined as broken. I do *not* need automatic route finding, although I suppose it would make sense to be able to add seperate software for that later. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 2 Jun 2007
Number::Phone releaseThere's a new release, version 1.58, of Number::Phone, my set of perl modules for picking information out of phone numbers. Changes from the previous release are that Mayotte, Reunion and Comoros can't decide which country is which, and there's the usual updates to the database of UK numbers, mostly to support the new 03 numbers. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 27 May 2007
New Bryar featureI just added support for specifying keywords (which the cool kids call "tags") in your Bryar postings. Please see if you can break things while I test them on this journal. Please note that I've not yet added keywords to my old postings. That will take quite a while to do, so please be patient. At the time of writing, keywords 'bryar' and 'whisky' should do vaguely useful things. You can even subscribe to keyword RSS feeds, like this. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 1 May 2007
Things Not SentThis evening, I wrote the following in response to some trouble someone was having with their mail on one of my mailing lists, one which is normally devoted to talk about electronic circuits. In the end I didn't post it, which is probably a good thing.
Gosh, Evil Dave showing restraint. Whatever next?!!? | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 17 Apr 2007
Phone advice wantedMy trusty old 6310i is giving up the ghost so I need a new phone. And I might as well combine it with a PDA. Being a long-term Palm user I'm inclined to go for the Treo 680 (or whatever is the studliest Palm OS version is - not Windows because I'm not stupid). Specific questions I'd like answers to, and which I can't find on Palm's webshite, are:
Your time starts now, please use both sides of the paper. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 16 Mar 2007
Dear ApplescriptYou're a retarded buggy undocumented piece of shit. Please fuck off and die slowly and painfully, impaled on a rusty shit-smeared spike. The same goes for the utter fuckwits who designed you. I hope their families die too so they can't spread whatever defective genes spawned a moron like you. Hugs n Glasgow kisses | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 15 Mar 2007
Vampire ElectronicsFor the last couple of days, my wireless network has been rather unreliable and I've been trying to figger out why. It turns out that an Apple Airport base station which flidded out a couple of years ago, and which I never unplugged because it was buried amidst a tangle of other cables, has spontaneously risen from the grave and is now working. It was breaking shit because it was on the same IP address and announcing the same SSID as the machine that had replaced it as my wireless router. How odd. (If you object to my use of 'flid' above, please read 'spaz' instead) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 20 Feb 2007
The value of backupsYesterday, my file server crashed badly. I hit the per-user process limit, so couldn't log in remotely, couldn't log in on the console - and so couldn't do a graceful shutdown. So I cycled the power. When it came back up, one of the filesystems was a bit buggered, as expected. But it was a bit more buggered than I first thought and couldn't be recovered. So I Rsnapshot FTW! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 13 Feb 2007
Number portabilityRecently, OFCOM asked for remarks about number portability. My response is here (PDF). The free software that I refer to in that page is my Number::Phone::UK module on the CPAN, which you can see in action here. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 26 Jan 2007
XML::Tiny releasedI have released my XML::Tiny module. The parser at its core is less than twenty lines of code. Pretty easy to follow code too, I think, and that also includes error handling. One of my aims in writing it was to keep memory usage and code to the absolute minimum, so it doesn't handle all of XML. The documentation says that it supports "a useful subset of XML". Personally, I think it supports the useful subset. It's certainly enough to parse the data I get back from Amazon when I use their web services, and to parse an RSS feed. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 20 Jan 2007
New Bryar releaseAs I've been promising to do for ages (it's over a year since Simon said I could take over maintenance of it, and several months since I promised Bob that he could have all the shiny new features I had planned) I've finally got round to releasing a new version of Bryar, the software what provides the brains behind this 'ere august journal. The most important change is that I released the stuff for filtering out comment spam. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 16 Jan 2007
Measuring speed in the digital ageIn the digital age, accuracy and speedy calculations come from using powers of two. You also want to stick with integers to avoid rounding error. Therefore I propose that we measure speed in nano-furlongs per mega-fortnight. The conversion from metres per second is fairly simple - 1 m/s is approximately 264 nFurlong/Mfortnight. This means that we can measure incredibly slow speeds with great precision - down to of the order of 10-19 m/s without having to enter the dangerous world of floating point. And of course we can easily measure all the way up to the fastest possible speed, that of light, which is only about 292 nF/MF. This provides ample room for further expansion of the measuring stick if Mr. Einstein turns out to have been wrong. A 128-bit value would let us measure speeds up to 1010 times that of light, in extremely small increments. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 14 Jan 2007
Dear AmazonYou're a bunch of cunts. Not only do you provide no way for me to export my wishlist to XML or CSV or anything useful like that, you manage to break all the third-party applications that do it as well. I hate you and hope you die. update: they had for no apparent reason disabled my account, although they were still sending me information about how to use it. It would have been nice if they'd told me. It would have been nice if I got helpful error messages back from the Net::Amazon module too. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 5 Jan 2007
Permalink | 0 Comments | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 10 Oct 2006
Debian is being stupidOh dear. Read this and this. I think the Debian developers should:
I'll certainly not be installing their brand of madness again. These days, Ubuntu is sufficiently mature. And while I'm venting my spleen (what on earth is a spleen, how do they vent, and do they taste nice?) Debian should sodding well fix their stupid release names. What the fuck is 'sid' or 'buttplug' or whatever they call it? What's wrong with a nice simple '5.7'? | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 28 Sep 2006
mod_bandwidth for teh win!!!!Most of you will not be aware that I run a mirror at home of recent episodes of The Linux Link Tech Show. Whenever there's a new episode, or they get slashdotted, my DSL gets hammered which means that I get a really sucky slow connection for anything I want to do to the rest of the world. So a few weeks ago I installed and configured mod_bandwidth. It didn't appear to work and I left it until later to fix it. I have now fixed it, by the simple expedient of turning it on by HUPping Apache. Doh! I've not imposed much of a restriction - the tllts mirror can eat up to about 97% of what's available, leaving just enough for me to do important things like ssh to this 'ere web sewer of mine and witter in my journal. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tue, 26 Sep 2006
Paypal's anti-phishing adviceOh dear. I just got email from Paypal (and yes, it really is from Paypal - I, unlike most people, know how to check it out properly) advising me about how to protect myself from being ripped off by fraudsters sending spam emails which merely claim to be from Paypal but which actually direct you off elsewhere so they can steal your Paypal username and password. This practice is commonly known as "phishing". Trouble is, to an unsophisticated eye, phishers' emails look just like Paypal's real emails. What Paypal should do is simply never email their customers except in direct response to the customer doing something on their site, such as sending someone some money. That way, less technologically-literate customers can simply ignore all unexpected mails "from Paypal" and be safe. That behaviour is good enough for my bank, so I wonder why Paypal don't do it. And before anyone mutters about what would happen if someone sends me money (which I obviously want to know about) - the person sending it should tell me. And I'll probably make an exception for when I'm selling something through ebay too. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 10 Sep 2006
PrecisionToday I was at precisely 0°0'0". Greenwich is cool. I yelled very loudly "THE WORLD IS MEASURED FROM HERE". Aside from the museums, it is teeming with fine pubs, at which I got very precisely tipsy. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 3 Sep 2006
Journal now with 30% more shiny!Look on the right! The list of all my archived posts has been broken down by year. By default you'll see archived posts from the current year, clicky-clicky on the numbers at the top to get previous years. It's all done with CSS and Javascript, so I only needed to fiddle with the templates and not with the application that drives the journal. And of course it degrades gracefully and everything is still available in non-CSS non-Javascript browsers. I even tested it in lynx. Hooray! I've also slimmed the page down considerably by using a named style for journal entry links instead of embedding style info in the page for every link, and for archived entries have reduced the length of their links considerably using the <BASE HREF> tag. That gave a weight reduction of something like 40%. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sat, 2 Sep 2006
YAPC::Europe 2006 report: day 3There were quite a few interesting talks in the morning, especially Ivor's one on packaging perl applications. Oh, and mine about rsnapshot, of course, in which people laughed at the right places and I judged the length of it just right, finishing with a couple of minutes left for questions. At the traditional end-of-YAPC auction, I avoided spending my usual stupid amounts of money on stupid things, which was nice. Obviously the hundred quid I put in to buying the hair style of next year's organisers wasn't stupid. Oh no. Definitely not. An orange mohican will suit Domm beautifully. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fri, 2 Jun 2006
Stupid spammersIn the last month, there have been well over 400 attempts at spamming this journal. All have failed. And yet the spammers still try. And I get email notifying me each time, because there's always a possibility that a legitimate comment might get classified as spam and need to be manually approved. Ah well, I have the IP for each of those 400-odd spams, and using routeviews.org I can easily turn them into a considerably shorter list of netblocks. And then auto-create a shitload of | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thu, 4 May 2006
To all my readers who use a sane calendar ...At the time of posting, it is exactly 01:02:03 on 04/05/06. Happy counting day! May you never run out of fingers and toes! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wed, 5 Apr 2006
To all my American readers ...At the time of posting, it is exactly 01:02:03 on 04/05/06. Happy counting day! May you never run out of fingers and toes! | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sun, 2 Apr 2006
Some implementation notes ...I've written up some notes on how this site works. It includes a very basic HOWTO on using mod_rewrite to protect data. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||


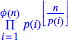
{kind=link}